Traditional DWH: Extract, transform, load
Setting up a data warehouse (DWH) in which the required operational data is saved, prepared and analyzed used to be a tried and tested solution pattern for fulfilling settlement-oriented information needs.
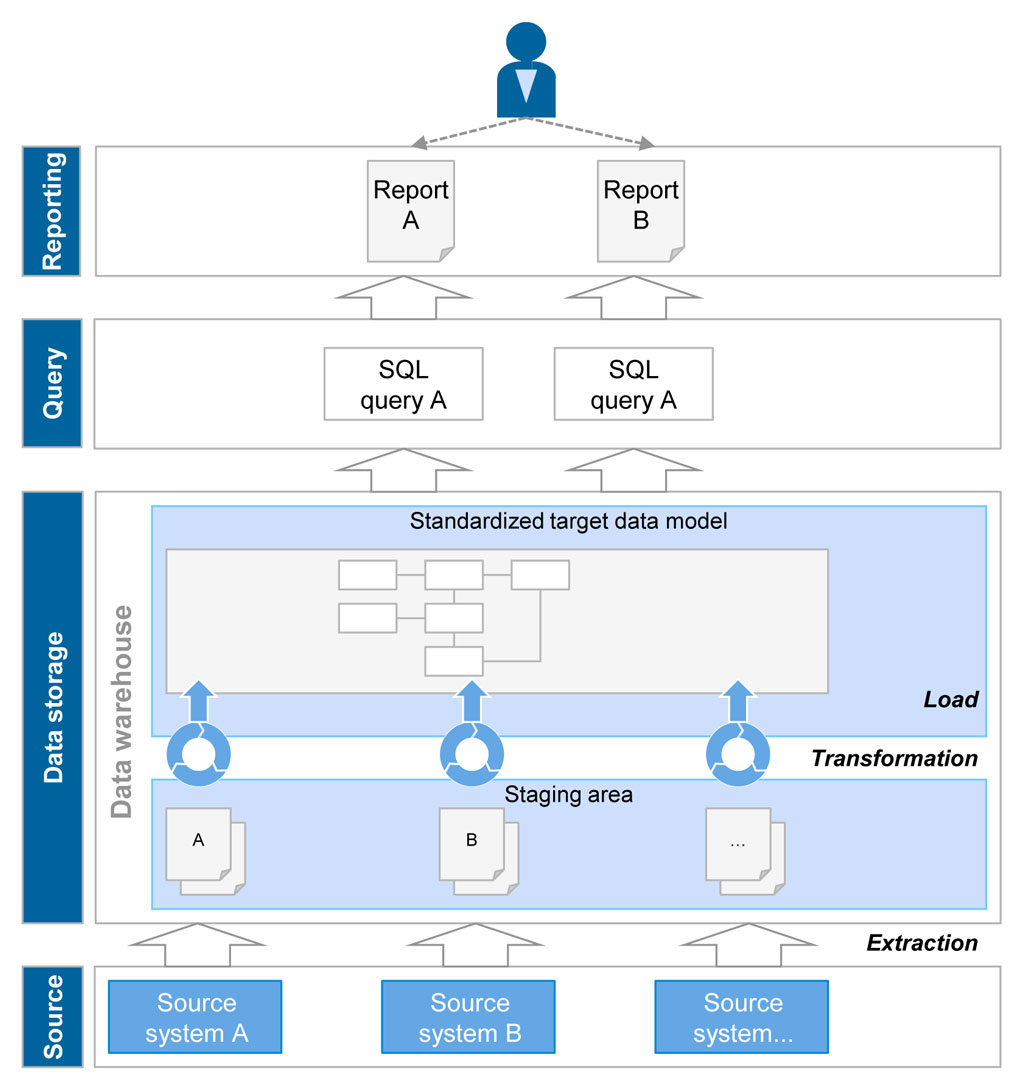 Figure 1: Draft of principles of traditional DWH architecture
Figure 1: Draft of principles of traditional DWH architectureThe required operational data is selectively extracted from the source systems and buffered on the entry level of the DWH (staging area). The extraction is usually made at regular intervals (daily, monthly, …) and at fixed dates (e.g. after final daily processing). Data is incrementally prepared, standardized and transformed in the target data structure within the DWH. The target data model is afterwards persisted whereas the initial data is usually overwritten with the next loading. Analyses exclusively access the target data model that comprises a consolidated view on the corresponding data warehouse. A relational database management system with a standardized SQL access for queries serves as a technical basis for a traditional data warehouse.
However, this concept reaches its limits with an increasing scope of requirements.
- High level of implementation efforts: The transformation and standardization of the initial data in a harmonized data model represent the core of the DWH concept. This procedure leads to a comparatively high level of implementation efforts since the target data model has first to be elaborated and discussed at large. Afterwards, each transformation has to be described in terms of its concept, implemented and tested before specific analysis can be conducted.
- Restricted flexibility: Solely the target data model defined beforehand is available for the analysis in the traditional data warehouse. A flexible integration of additional data sources, e.g. for ad-hoc analyses is usually not possible and has to be conducted outside the DWH environment.
- No raw data: The aim of a data warehouse is the standardization and similar mapping of comparable issues in order to simplify analyses at a later stage. This often makes sense for regulatory issues or in the fields of bank management (e.g. standardized mapping of all credits) but contradicts more operational requirements where detailed information on individual products is required (e.g. specific conditions for construction financing).
- Data volume: Basically, data warehouses can deal with huge amounts of data, however, need special database and storage hardware if the scope increases. Thus, the costs typically grow exponentially in case of major data volumes.
Data lake: First load, then transform
The data lake concept provides a remedy by making all required data for analysis purposes available at one place in a central and unchanged manner. In the next step only, a selective data preparation within specific analyses takes place. In this context, performing, flexible and cost-efficient processing is to be ensured by using big data technologies.
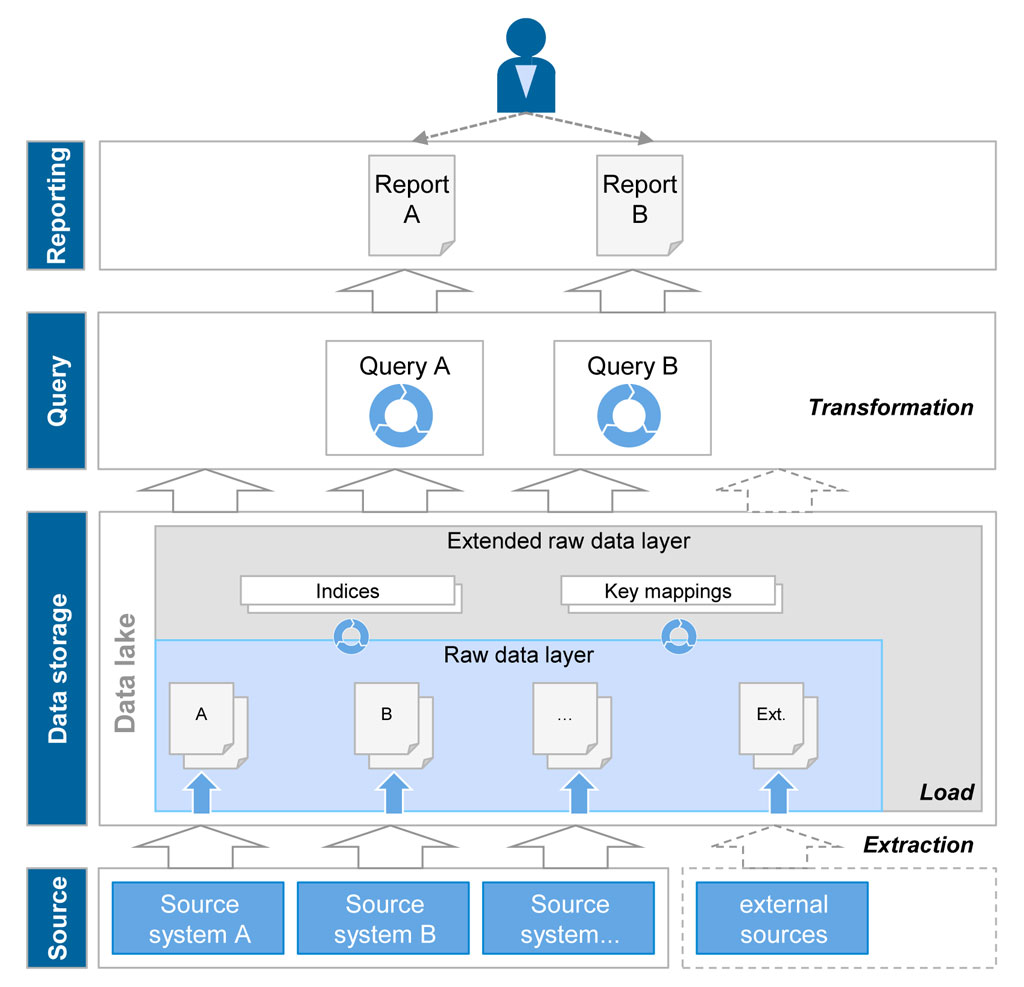 Figure 2: Draft of principles of data lake architecture
Figure 2: Draft of principles of data lake architectureThe initial data of the source systems is directly loaded into a raw data layer pursuant to the data lake concept without any logical transformations. The technology is usually not based on a relational database but on file system structures (Hadoop) or key value structures due to the aforementioned restrictions. Both approaches offer the advantage to dynamically deal with structural changes on the part of the source system and to process heterogeneous data formats (also unstructured). The raw data is, if needed, supplemented by key mappings or indices in an expanded raw data layer in order to allow for performing access, but doesn’t change its structure. Queries and analyses are directly made on the raw data layer but are much more complex in comparison with the traditional DWH since the harmonization and consolidation of information (transformation) have to be made as part of the queries in this context. Various big data technologies are available for defining and processing these queries that ensure a high and cost-efficient scalability via distribution mechanisms based on standard hardware. Since the data transformation is only made at the term of the queries, a flexible integration of further data (e.g. external information) is quite easy. Usually external data is not persisted in the data lake but only published via a link in the metadata.
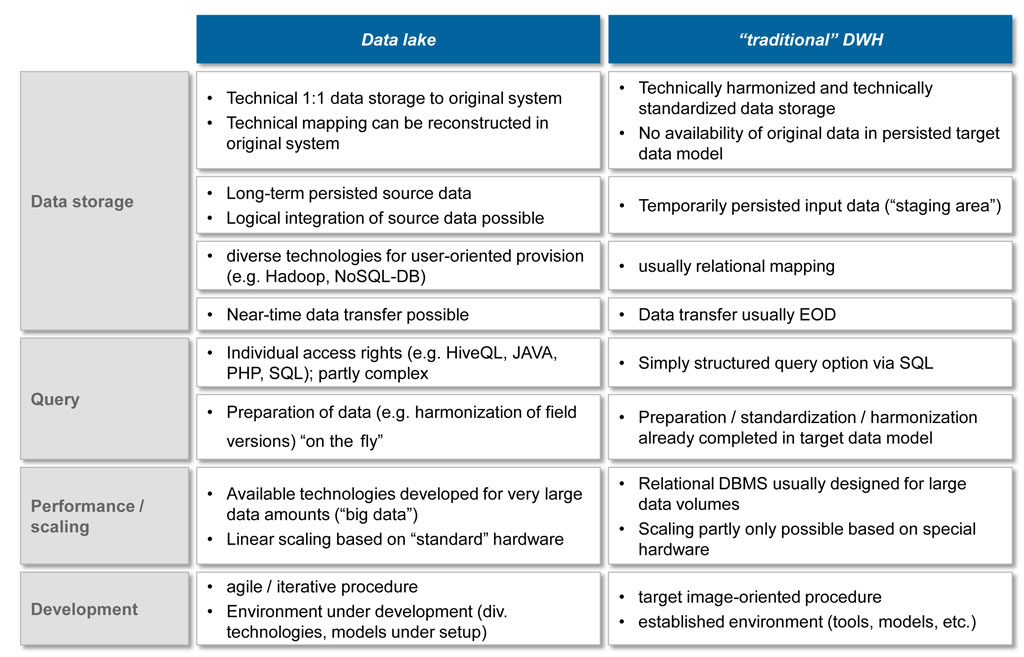 Figure 3: Comparison of data lake and traditional DWH
Figure 3: Comparison of data lake and traditional DWHPrerequisites for a data lake approach not to be underestimated
The data lake approach is a promising alternative apart from the traditional data warehouse concept, however, it requires the fulfillment of a series of framework conditions.
The metadata and its management play a pivotal role because they are indispensable for the dynamic and proper access to the raw data. In addition to a subject-related and technical description of the data lake content, the metadata is to contain also information whether the raw data can be merged and transformed. The creators of queries and/or the BI tool used have to be able to find out from the metadata if and how the customer data from system A can be combined with the product data from system B. A consolidated key relationship such as in the traditional DWH ensuring a standardized combination for all analyses is not provided in the data lake.
As a result, the overall requirements for the users of a data lake are on the increase. Free analyses of data should only be carried out by experts (data scientists) who know the relationships of the raw data very well. Predefined queries and reports or sub-data portfolios with a comprehensive metadata description, however, can be used by several users. Thus, the data lake often differentiates between an exploratory expert area and a secured user area. All in all, it can be concluded that complexity and expenses are shifted from data storage to report and analysis setup.
Besides, a major challenge is the security issue. The benefits of the data lake increases the more detailed and varied the available data is. At the same time, not all users should be granted access to the entire data warehouse of an institution, in particular from compliance perspective. This requires respective security mechanisms restricting the access as far as needed, but as little as possible.
Requirements define the right concept
The question of the better concept for providing operational data for analyses cannot be answered in a general way but depends on the specific requirements. If the aforementioned framework conditions for setting up a data lake can be fulfilled, this concept can be used for the following requirements:
- Access to original data structures: The provision of raw data is a core element of the data lake concept. Depending on the historicization and replication concept, raw data with a long history and/or single changes of the state can be made available. Typical use cases can be found, for instance, in the fields of Compliance and Auditing.
- Low standardization degree: The advantage of this concept is the high level of flexibility for queries and analyses on a broad data basis that is, for example, required for issues in the fields of data mining and data exploration or for ad-hoc queries in the regulatory context (QIS, AQR). The concept can also be used for standard queries. Here, the traditional data warehouse offers specific advantages due to the transformation of the data beforehand.
- Major data volume: The implementation of the data lake concept is based on the use of big data technologies that were especially designed for dealing with major amounts of data. Apart from the high performance via distribution mechanisms, the cost advantages from the usability of standard hardware become apparent, too.
- Neartime availability: Raw data can be timely provided thanks to the lacking transformation necessities. A nearly simultaneous data provision of the data lake is made possible via specific replication mechanisms, if necessary. Consequently, the data lake can be used as a data source for online banking, for example, without increasing the burden for the operational systems.
The traditional DWH still has its strengths if the analysis focus has a defined scope and if standardized queries are made oftentimes. It is also the preferred concept if a consolidated overall view is required that has to be consistently queried from different users.
Both concepts can be combined in a sensible way. Thus, a data lake can serve as a staging area for a traditional DWH since the raw data only has to be provided once for different requirements and is available for a long time. At the same time, the target data model of a DWH can be made available in the data lake which provides its consolidated data warehouse for more flexible analyses.
A data lake can be set up as addition to the existing DWH and can be incrementally integrated in the existing system landscape.
