Typical problems in the development and operation of ML-based software
In classic organizations, the software produced is often difficult to operate, because the development team is not involved in operations and consequently has no incentive to create easily operable software.
With ML-based software, the discrepancy between dev and ops is even greater. Developing ML-based software (called “training an ML model”) inherently requires dev teams to experiment. They need to be agile. On the other hand, operating ML-based software requires stability.
In addition, non-automated artifact management, as well as non-automated test, build and release processes slow down and demotivate the dev team. This severely impacts development velocity and causes software releases to take a long time, be unstable and involve a lot of manual effort. A tedious release process requires a rigid release schedule, which in turn limits the time to market for new features. This means, that cumbersome release processes make it slow for your IT to release new features, which in turn limits time-to-market and the speed at which you learn about your customers’ preferences. Ultimately, this results in wasted earnings potential and reduced customer satisfaction.
For ML-based software, this issue is even more serious. Since the training of ML models involves more moving parts than with classic software, the non-automation of artifact management and of test/build/release processes is more cumbersome for ML-based software. The additional moving parts include data selection, data preparation methods, model architecture selection, etc.
Unlike classic software, ML models have a natural tendency to decay in production. They are trained on data, which is a representation of reality at a specific point in time, and only works as intended with data that is roughly similar. For example, when user behavior changes, the ML model won’t know how to deal with that. Therefore, there is an increased need for monitoring and retraining ML models.
Finally, one of the main advantages of ML models is that they can get better in the course of time. We can collect more data over time and use it to improve the model. However, this also means that there are naturally more triggers for change than with classic software. Which, in turn, also implies a higher need for frequent retraining and redeployment.
Solution: MLOps cycle analogous to DevOps cycle
To solve the above issues – those it shares with classic software and those specific to ML – we can use the MLOps cycle as a thought framework.
As an application of DevOps, MLOps has the same cycle phases. The content in each phase, however, differs from that of classic DevOps.
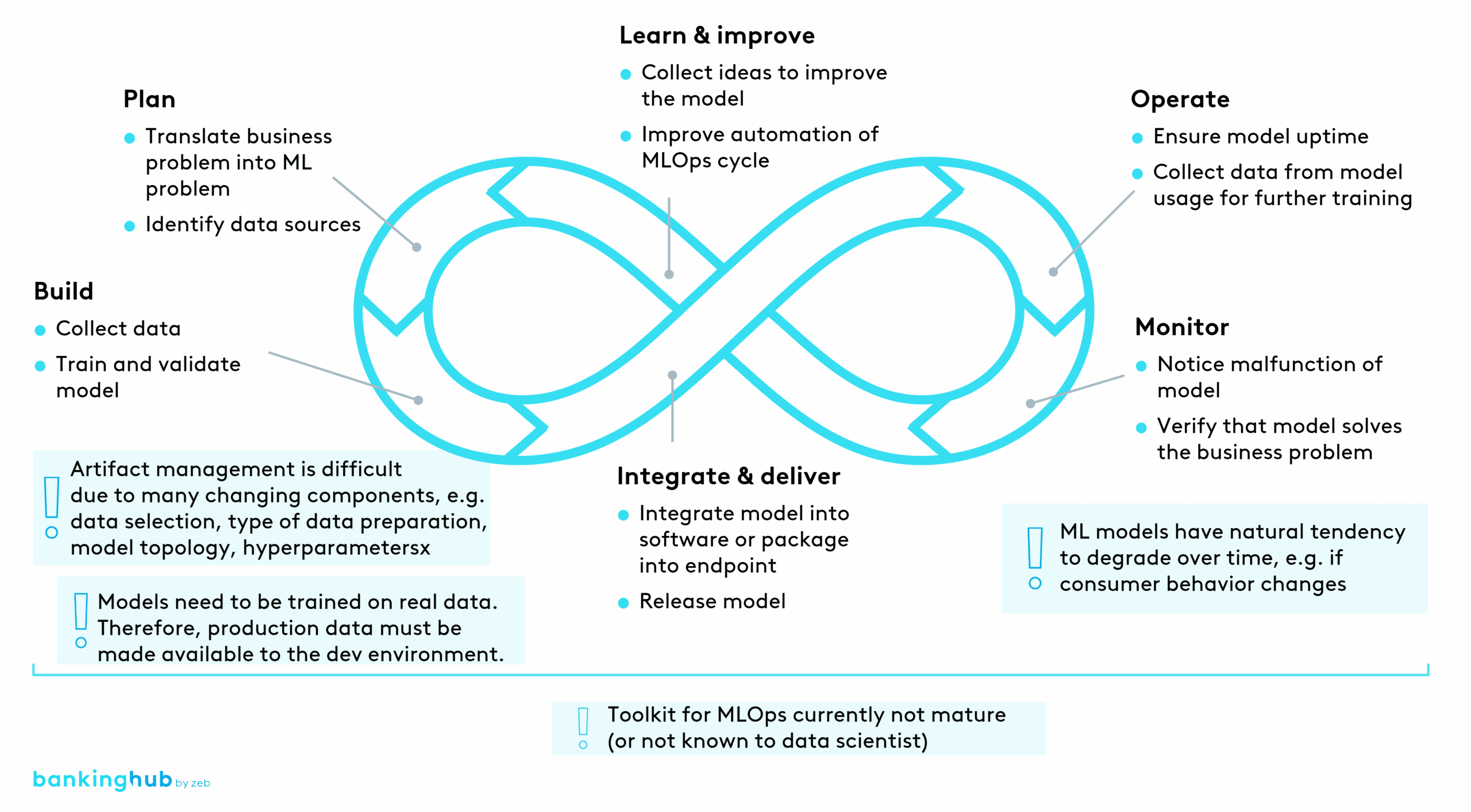
When you decide to implement MLOps in your organization, make sure to consider the MLOps implementation holistically, including organizational structure, governance, tools and technology.
If you already have DevOps in place at your IT organization, there are three main issues you need to think about.
Firstly, you need to decide which tools you want to use. From our point of view, the current toolkit has not yet reached a sufficient degree of maturity, since MLOps is a relatively new topic, and the market is still evolving and consolidating. Therefore, you need to pay special attention to your specific requirements and verify that the tools you are considering can meet your needs. We also advise that you talk to other IT managers (or external advisors) who are already a step ahead on their MLOps journey.
Secondly, since ML models need to learn from real data, production data needs to somehow be exposed to a dev environment in a timely, compliant and secure manner. This means that you need to think about what new roles and permissions need to be defined, how to make data accessible from a data model perspective (aggregated, pseudonymized, fully visible) and from an architectural perspective (which ETL processes need to be adapted?).
Thirdly, you need to think about whether your ML development velocity matches your business requirements. As ML models have a natural tendency to degrade over time (e.g. in case of changes in consumer behavior or in the type of documents to be parsed), the model needs to constantly be retrained and redeployed. If your processes are too slow, your model may well already be outdated at the time of its deployment. You therefore need to determine the ‘freshness’ requirements of your models and match your ML development velocity accordingly. The freshness requirements are derived from the business problem you are aiming to solve.
Example deep dive: toolkit
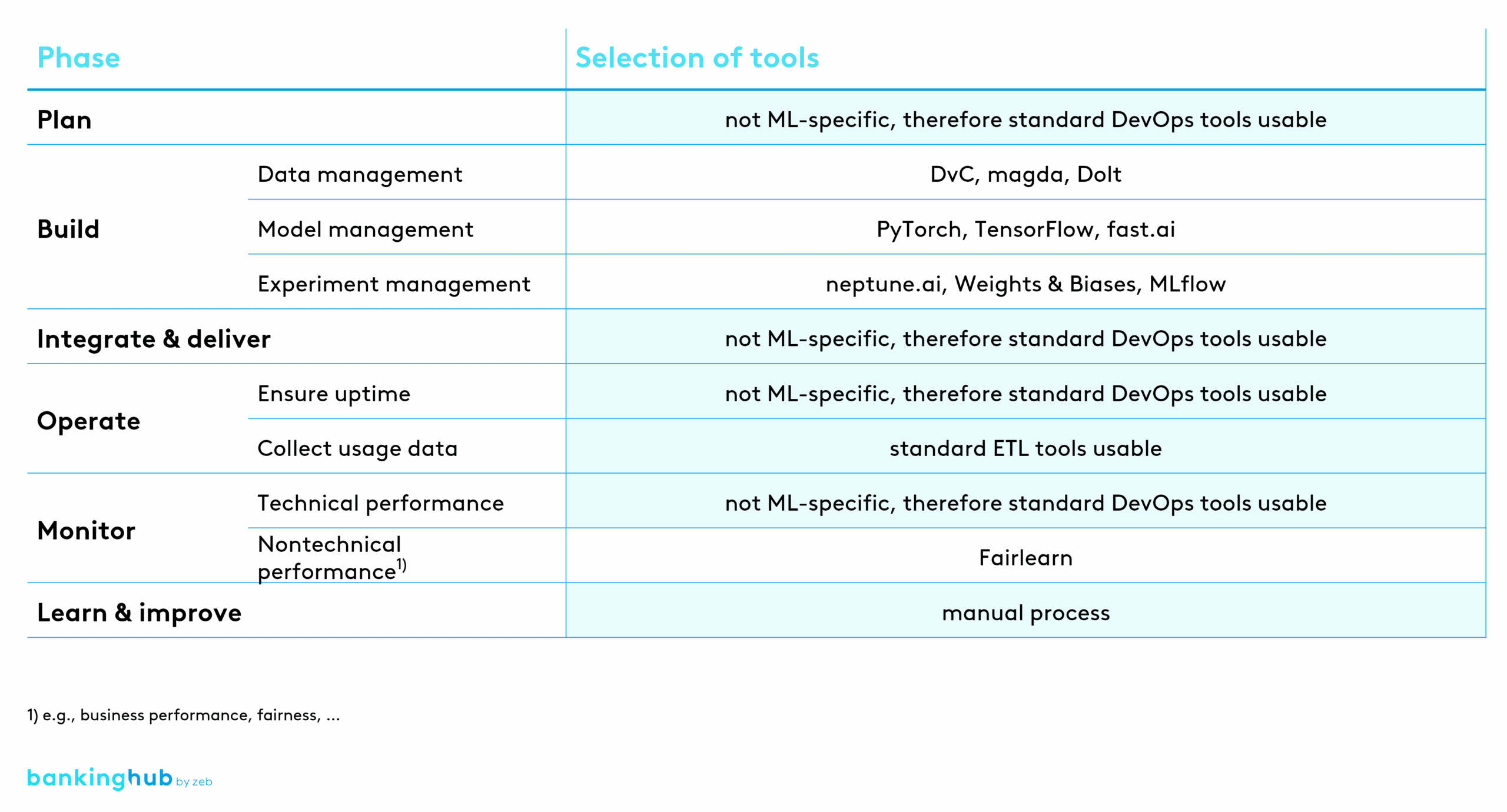
As you can see in the table above, not all phases of the MLOps cycle require ML-specific tools. It is often possible to use DevOps tools instead. There are, however, phases that are very ML-specific – especially “Build” and, in parts, “Monitor”.
Conclusion on MLOps
As mentioned in the introduction, ML-based software is here to stay and will only increase in importance. However, ML is not a magical creature that cannot be tamed. On the contrary, many rules of traditional software engineering can be successfully applied to ML-based software. The MLOps toolkit is available in the forms of systems, processes, and tools. IT managers must now determine the right time for their organization to take the leap. In doing so, they will be able to achieve and maintain efficiency gains.




