Data lakehouse combines data warehouse and data lake
The term “data lakehouse” consists of the well-known concepts of data warehouse and data lake and describes an approach that combines the advantages of data warehouse and data lake in a common platform.
Architectural concept data warehouse
The traditional data warehouse is designed and developed for specific applications – e.g. regulatory reporting, risk management or sales management. It is modeled based on the requirements for these applications and connected to appropriate source data.
As a rule, the data is quality-assured, transformed and stored in a structured form in a target model and logged there. The input data is usually volatile and is deleted after processing. With the target model, a single point of truth is created. Most institutions use relational databases to store and transform data.
In practice, the operation and expansion of a data warehouse are often associated with high costs for data integration and harmonization as well as for hardware and storage.
Architectural concept data lake
Data lakes have become established as a consequence of the increasing flood of data and rising requirements with regard to data usage (volume, structure, temporal availability/latency) – for example through AI applications. When designing a data lake, there are usually fewer specific use cases.
Source data is not only collected based on specific use cases, but data is “stockpiled” to be used sooner or later. All possible data (also pictures, videos, communication, etc.) is connected and stored in the landing zone as well as logged there.
The raw data is only processed and transformed when it is used for specific use cases (schema-on-read concept). The recipients of the processed and transformed data are often modern advanced analytics methods (AI).
Advantages: data warehouse vs. data lake
Both concepts of data warehouse and data lake have their own advantages:
Data warehouse advantages
- The data is available in a structured, standardized and consumption-oriented form. The business user can assume that the same data from different source systems is harmonized and logged in the target data model.
- The data is usually quality-assured.
- Different techniques like caching or indexing allow for a high-performance access.
- The database management systems ensure transaction security (“ACID” transactions).
- Typical data warehouse systems have finely tunable security and governance features, such as access control and audit logging.
Data lake advantages
- Structured, semi-structured and unstructured data can be collected and persisted without (much) modeling and transformation effort.
- Users can directly access the raw data and process it as needed.
- The file system of a data lake can be implemented on scalable and cost-effective storage hardware/software.
- Well-designed solutions are scalable and optimally built in a cloud-native manner so that they allow for cost-effective and performance-optimized options for operation.
- Establishing many powerful open-source tools reduces costs and enables faster software updates.
Advantages of data lakehouse
The data lakehouse concept combines many advantages and also promises dedicated added value.
To take advantage of both platforms, some FSPs are using a multi-level architecture of both approaches, i.e. both data warehouse and data lake are in use.
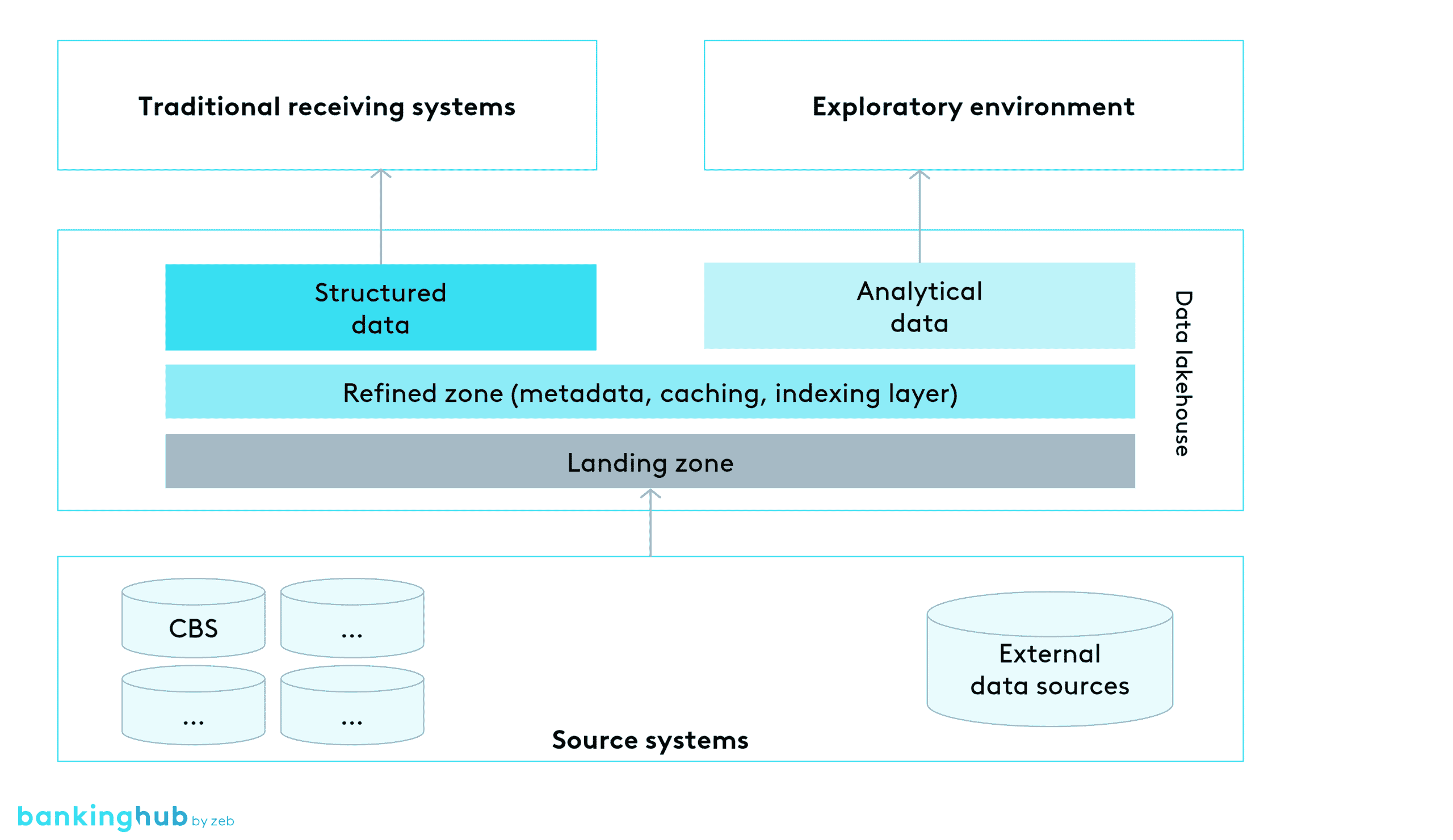
The data lakehouse approach now promises a combination of data warehouse and data lake on a common platform, as opposed to separate systems.
In simple terms, a collection and logging of raw data is organized in the data lakehouse. Above this is a harmonized, quality-assured and logged layer (often referred to as the refined zone), which is similar in content to the core data model of a data warehouse. This layer supplies the traditional applications, calculation engines and reports. The data for productive data analytics use cases is also included there, which must also be sufficiently quality assured and under governance. The exploratory functions of the data analytics discipline can access data from the raw data layer and the refined zone.
Additional potential of the data lakehouse
In addition to the dedicated advantages of data warehouses and data lakes, additional potential can be leveraged:
More uniform toolkit: for separate operation of individual data warehouse and data lake platforms, a number of different tools and techniques are used, partly for similar tasks. The data lakehouse approach offers the potential to reduce the “tool zoo” created in this way, i.e. to save licensing costs and reduce the requirements for tool-specific knowledge of employees.
Reduction of redundant data storage and business logics: depending on the use case considered, data is sometimes stored redundantly in data warehouses and data lakes and created in conjunction with duplicate logics. With a data lakehouse approach, this redundancy can be avoided.
Simplification of data governance: harmonization in a data lakehouse reduces the number of systems and redundant data storage. This can enable simplification of data governance by reducing system boundaries and avoiding data ownership conflicts between redundant data.
Reduction of ETL routes: in a multi-level data warehouse and data lake architecture, data often needs to be exchanged between both platforms. In a data lakehouse, data exchange between platforms is eliminated, which in turn can reduce costs and complexity.
Hardware/operating costs: the approach has a high potential for significant cost reduction (hardware/operation), especially if design and implementation are cloud-native. Thus, it offers a high degree of flexibility for further expansion and the use of “computing load on demand”.
Don’t be fooled
Despite many advantages, there are a few arguments against a new data architecture – but don’t be fooled!
One the one hand, the holistic view of the aforementioned advantages and opportunities opened up by the data lakehouse concept should convince everyone dealing with data architectures and their efficiency. On the other hand, of course, even good concepts can be poorly implemented.
As mentioned at the beginning, many institutions face the problem of a historically grown data architecture with existing data warehouses and possibly also already established data lakes. The first reaction of many decision-makers, architects and those responsible for change and run may be not to question the existing architecture, i.e. to succumb to the unconscious status quo bias. This tendency is confirmed by a number of “good” arguments against a new data architecture: the risks are too high, the conversion is too expensive, large investments have already been made in the existing solution, the workforce’s know-how is not designed for this or the existing solution is sufficient to support the business strategy, especially since the IT strategy does not even mention a data lakehouse.
The above objections (and the list is not exhaustive) are certainly applicable to many institutions at the current time. At the same time, managers and decision-makers must constantly question how they can keep their company or area of responsibility fit or make it fit for the future. Against this backdrop, the above-mentioned objections must be rationalized and weighed against their opportunity costs. Necessary changes must not be rejected and important IT trends must not be missed out on.
Conclusion: data lakehouse
Review your IT strategy and set the right direction!
We don’t want to expand the repertoire of phrases regarding the ever more rapidly developing requirements and the constantly growing possibilities of digitalization at this point. Many companies already define a business strategy and their IT strategy accordingly, both of which must be regularly reviewed and adjusted. If one compares the current capabilities of one’s own IT architecture with the anticipated future requirements of the business side (or the supervisory side), many institutions will have to look for possible medium- and short-term solutions. In the data architecture area for planning purposes of financial services providers, a data lakehouse is likely to be part of the fit-for-future solution.
Of course, the question then arises as to the individual specific approach. In our experience, a “throw away and build new” approach is usually not the right way to go, especially because of the high costs and risks involved. Whenever the question focuses on specific aspects, different measures can be found quickly instead, enabling successive development towards the target picture.


